FastAPI Hugging Face GPU involves deploying Hugging Face models using FastAPI with GPU acceleration for faster inference. FastAPI efficiently handles API requests, and using a GPU boosts performance, especially for tasks like NLP.
This article explains how to deploy Hugging Face models using FastAPI with GPU acceleration for faster processing. This setup improves speed and performance for tasks.
Inference API for Text Generation
The Inference API for text generation lets you use machine learning models to create text automatically. You can send a request with some input text, and the model will generate more text based on it. This is useful for chatbots, content creation, or other text-based tasks.
Expose the API Server to the Internet
To expose an API server to the internet, you make it accessible from anywhere online. This usually means putting the server on a cloud platform or using a public IP address. It allows users or apps to connect to your API from different locations over the internet.
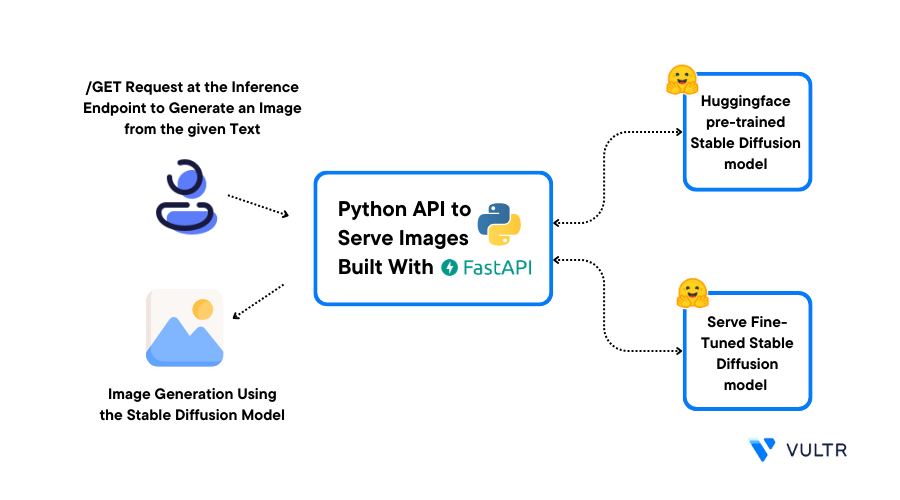
Serve Fine-tuned Models
To serve fine-tuned models means making customized machine-learning models available for use. These models are trained for specific tasks, like text analysis or image recognition.
By serving them through an API or web service, users can send data to the model and get results in return.
Read Also: GPU drivers crashing – Resolve Crashes 2024!
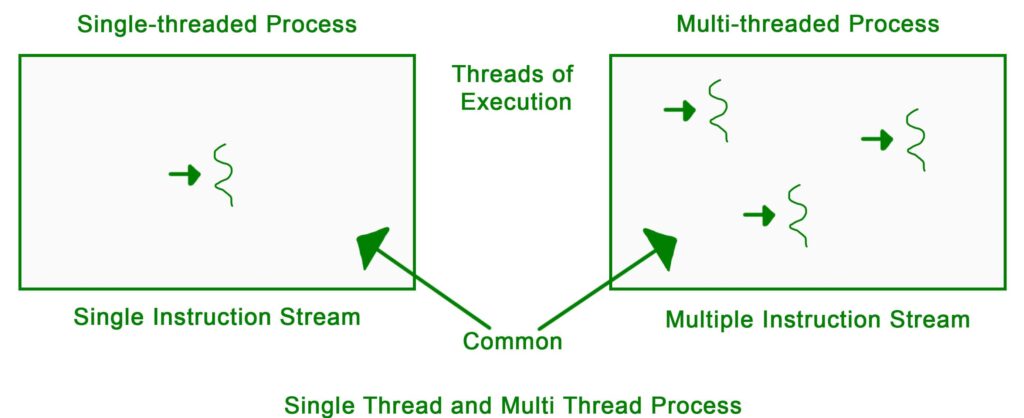
Multithreading
This technique is where a program runs multiple tasks (threads) at the same time. This helps the program do more work faster by using the computer’s resources more efficiently.
For example, one thread can handle user input while another processes data, making the program run smoothly.
PyTorch and FastAPI optimizations
Optimizing PyTorch with FastAPI helps improve the speed and efficiency of serving machine learning models. You can use techniques like loading models onto a GPU, adjusting batch sizes, and using asynchronous requests in FastAPI.
These optimizations allow faster responses and better performance in real-time applications like text or image processing.
Changes to PyTorch configuration:
These include setting the model to use a GPU, adjusting batch sizes, or modifying training parameters. These adjustments help improve performance, speed, and memory usage when training or running machine learning models.
Read Also: How Many Degrees Is Overheating GPU – Act Fast!
Changes to FastAPI configuration:
They can involve setting up routes, adding middleware, or adjusting timeouts. These changes help improve how the API works, making it faster and more secure, while ensuring it handles requests correctly and efficiently for users.
Using GPU Spaces – Guide 2024!
Using GPU Spaces allows you to run machine learning models on powerful graphics processing units. This helps speed up tasks like training and inference, making it easier to handle large data and complex models quickly and efficiently.
Hardware Specs:
Hardware specs refer to the details of a computer’s parts, like the CPU, GPU, RAM, and storage. Knowing these specs helps you understand a computer’s performance and whether it can run specific software or handle certain tasks effectively.
Configure hardware programmatically:
Configuring hardware programmatically means using code to set up and manage computer parts like GPUs or CPUs.
This allows you to automate tasks, optimize performance, and adjust settings without needing to do everything manually, making the process faster and more efficient.
Framework specific requirements:
These requirements are the rules and tools needed for a particular software framework to work correctly. These may include programming languages, libraries, or specific hardware.
Understanding these requirements ensures you set up your environment properly for developing and running applications.
PyTorch:
This is a popular open-source library for machine learning and deep learning. It helps developers build and train models easily. PyTorch is known for its flexibility, allowing users to work with complex data and create custom neural networks for various tasks.
Read Also: Is It Bad To Stress Test Your GPU – Protect your GPU!
TensorFlow:
TensorFlow is a free tool that helps people create and train machine learning and deep learning models. It helps developers create and train models for tasks like image recognition and natural language processing.
TensorFlow is widely used for building AI applications and handling large data.
Community GPU Grants:
Community GPU Grants provide free access to powerful GPUs for developers, researchers, or students. These grants help people who need high-performance hardware for machine learning projects, allowing them to work faster and more efficiently.

Set a custom sleep time:
Setting a custom sleep time means programming a pause or delay in a task for a specific amount of time. This is useful when you want a program to wait before doing something, like repeating a task or processing data.
Pausing a Space:
Pausing a Space means temporarily stopping an online application or project, often to save resources like CPU or GPU. During the pause, the app is inactive but can be resumed later without losing progress or data.
Set up the Server – Guide Us Now!
Setting up the server involves configuring a computer to manage and deliver data to other computers over a network. This includes installing necessary software, adjusting settings, and ensuring the server can handle requests from users or applications efficiently.

Benchmarking setup – About Us!
Benchmarking setup means preparing a system to measure its performance. This involves running tests on hardware like CPU, GPU, or software applications to see how fast they work.
The results help compare systems or identify areas for improvement, ensuring the best performance for specific tasks.
Performance Testing
Performance testing is a process used to check how well a system, app, or hardware works under different conditions.
It measures speed, stability, and response times to ensure everything runs smoothly, even with heavy usage, helping find and fix any performance issues before deployment.
Frequently Asked Questions:
1. What is FastAPI, and how does it work with Hugging Face models?
FastAPI is a web framework for building fast APIs. It works with Hugging Face models by allowing you to deploy machine learning models as APIs, letting users send data to the model and receive results like text or image analysis.
2. How can I deploy Hugging Face models on a GPU using FastAPI?
To deploy Hugging Face models on a GPU using FastAPI, load the model on the GPU (e.g., using PyTorch with a model.to(‘cuda’)), and set up FastAPI to handle API requests. This speeds up model processing for tasks like text or image analysis.
3. Can I serve multiple Hugging Face models using FastAPI with GPU acceleration?
Yes, you can serve multiple Hugging Face models using FastAPI with GPU acceleration. By loading different models onto the GPU and setting up separate API routes in FastAPI, you can handle requests for multiple tasks like text generation or classification.
4. Are there any specific FastAPI configurations needed for GPU deployment?
Yes, specific FastAPI configurations for GPU deployment include setting up asynchronous requests, adjusting timeout settings, and ensuring proper resource management. This helps optimize performance, allowing FastAPI to efficiently handle multiple requests.
5. How do I ensure that FastAPI utilizes the GPU for Hugging Face models?
To ensure FastAPI utilizes the GPU for Hugging Face models, load the models onto the GPU using PyTorch e.g., model.to(‘cuda’). Also, confirm that your server has the necessary GPU drivers and libraries for proper functioning.
Conclusion
In conclusion, Deploying Hugging Face models with FastAPI on a GPU significantly enhances performance and speed for machine learning tasks. This setup allows for efficient handling of API requests, enabling faster inference and better user experiences.